
Durante 2024 raro era el día en el que algún medio informativo no contenía alguna noticia relacionada con la llamada Inteligencia Artificial (IA). Al mismo tiempo se produce un importante aumento de empresas y tecnólogos que se proclaman expertas en IA. En los anuncios de TV observamos vehículos con IA, frigoríficos con IA, páginas web creadas mediante IA, etc. En resumen, indubitablemente podemos afirmar que la IA está de moda.
Intentaremos responder en este texto a las siguientes preguntas:
- ¿Cuándo empezó la IA?
- ¿Realmente qué es la IA?
- ¿Qué hay detrás de herramientas tan populares como chatGPT, Siri o Dall-e?
- ¿Qué problemas conlleva la IA?
Aunque se suele señalar 1956 como el nacimiento del término Inteligencia Artificial, se podría decir que el concepto adquiere cierta madurez con la creación en 1979 de la American Association for Artificial Intelligence. Sus equivalentes europeos (EurAI) y español (AEPIA) son respectivamente de 1982 y 1984. Es decir, se puede observar que la IA tiene más de 40 años de trayectoria establecida en la comunidad científica, y, por tanto, su novedad actual es para el gran público, pero no para la tecnología y la ciencia.
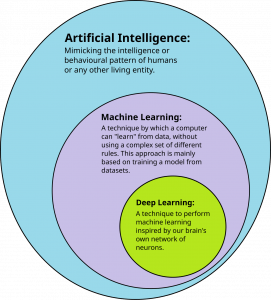
 Explicar qué es la IA no es sencillo. Realmente el concepto de Inteligencia Artificial ha ido teniendo distintas semánticas durante este tiempo. Por no divagar en exceso y atendiendo al concepto actual, se podría definir de forma simple que una herramienta es de IA si utiliza un algoritmo que produce un modelo parametrizado, entrenado para ajustarse a unos datos y que podrá ser inferido con datos nuevos. Esta definición es, en cierta manera restrictiva, pero expliquemos un poco más los conceptos anteriores para comprender por qué abarca a la diversidad de aplicaciones citadas anteriormente.
Explicar qué es la IA no es sencillo. Realmente el concepto de Inteligencia Artificial ha ido teniendo distintas semánticas durante este tiempo. Por no divagar en exceso y atendiendo al concepto actual, se podría definir de forma simple que una herramienta es de IA si utiliza un algoritmo que produce un modelo parametrizado, entrenado para ajustarse a unos datos y que podrá ser inferido con datos nuevos. Esta definición es, en cierta manera restrictiva, pero expliquemos un poco más los conceptos anteriores para comprender por qué abarca a la diversidad de aplicaciones citadas anteriormente.
El concepto de algoritmo es perfectamente conocido en este contexto: secuencia de pasos implementados en algún lenguaje de programación que se ejecuta sobre un determinado computador. Un algoritmo consta habitualmente de una entrada y produce una salida. En este caso la entrada es un conjunto de datos (que llamamos datos de entrenamiento) y la salida es un modelo completamente definido, que a su vez es otro programa informático.
Entenderemos por modelo un formalismo matemático que no está completamente definido. Es decir, este modelo tiene parámetros que son desconocidos a priori y cuyos valores deben ser determinados durante el llamado entrenamiento. Los modelos pueden ser muy simples, con unos pocos parámetros, o muy complejos, con miles de millones. Estos modelos constituyen una caja de herramientas habitual de la IA llamada Machine Learning (ML). Los modelos de ML van desde las simples rectas de regresión hasta los complejos modelos transformers, pasando por árboles o redes neuronales.
Entrenamiento se refiere al proceso por el que el modelo anterior queda completamente definido. Normalmente el algoritmo, en una secuencia iterativa, irá aproximando los valores de los parámetros para que el modelo se ajuste a los datos. Este proceso de entrenamiento es un mecanismo de optimización, guiado por una función de bondad que mide el ajuste del modelo a los datos. Las matemáticas y las heurísticas de búsqueda proporcionan diferentes herramientas para este proceso de ajuste. Una vez terminado el entrenamiento, el modelo queda completamente definido y suele ser proporcionado finalmente como otro programa informático para poder llevar a cabo la inferencia.
El concepto de datos es muy amplio, de hecho, en la actualidad casi todo son datos: una hoja Excel, una imagen, un vídeo, una página web, un pdf, o todos ellos juntos. Como es lógico cuánto más complejos sean los datos más parámetros necesitará el modelo para ajustarse y más complejo será el proceso de entrenamiento, necesitándose más potencia de cómputo y más tiempo.
El resultado de este proceso de entrenamiento sobre unos datos es un modelo completamente definido, en forma de programa de ordenador que permite realizar la fase de inferencia. La fase de inferencia consiste en proporcionar al modelo datos nuevos, normalmente distintos de los que se entrenó, para que el modelo nos devuelva el patrón que más se ajusta a los datos nuevos en función de los datos entrenados.
Veamos distintos tipos de modelos de IA empezando por uno sencillo y acabando con los últimos modelos de IA generativa.
 Un ejemplo habitual de modelo básico de IA de los años 90 es la determinación del riesgo asumido por un banco si concede un préstamo a un cliente. Los datos de entrenamiento lo constituyen las variables crediticias de clientes históricos a los que se le concedió un préstamo: ingresos, antigüedad en el trabajo, edad, propiedades, etc. El banco dispone de un modelo que se ajustó para aprender un patrón que establezca una relación causal entre las variables anteriores y el resultado del crédito. Este modelo está disponible de forma que, cuando un nuevo cliente solicita un préstamo, con sus datos concretos se puede tener una información que ayude al banco a calcular el riesgo de impago.
Un ejemplo habitual de modelo básico de IA de los años 90 es la determinación del riesgo asumido por un banco si concede un préstamo a un cliente. Los datos de entrenamiento lo constituyen las variables crediticias de clientes históricos a los que se le concedió un préstamo: ingresos, antigüedad en el trabajo, edad, propiedades, etc. El banco dispone de un modelo que se ajustó para aprender un patrón que establezca una relación causal entre las variables anteriores y el resultado del crédito. Este modelo está disponible de forma que, cuando un nuevo cliente solicita un préstamo, con sus datos concretos se puede tener una información que ayude al banco a calcular el riesgo de impago.
Ya entrado el siglo XXI se pudo pasar de datos numéricos a datos en formato texto o voz, en herramientas como los llamados asistentes virtuales (por ejemplo, Siri o Alexa). La base tecnológica de estos se corresponde con el proceso anterior. En primer lugar, se dispone de un modelo que fue entrenado para convertir lenguaje natural hablado en texto. Es decir, el modelo se ajustó comparando el sonido de palabras con su correspondiente texto durante la fase de entrenamiento, de forma que es capaz de convertir expresiones orales en su correspondiente expresión escrita. Este proceso se denomina Reconocimiento Automático del Habla o ASR por sus siglas en ingles. Una vez se dispone de un texto escrito se extraen las palabras clave mediante técnicas estadísticas y de ML. Esta tarea se denomina Reconocimiento de Entidades con Nombre o sus siglas en inglés NER. A partir de ellas, el asistente realiza una búsqueda en la web que crea un texto que, mediante el proceso contrario al ASR, permite obtener una respuesta hablada del asistente.
En este punto del texto, es probable que el lector esté muy despistado. ¿De verdad este proceso tiene algo que ver con chatGPT? Pues sí, tiene todo que ver. Hay un gran salto hasta 2022, pero el “mecanismo” es exactamente el mismo. La llamada Inteligencia Artificial Generativa sigue el mismo proceso de datos y entrenamiento de un modelo citado con anterioridad. Cuando usamos chatGPT estamos haciendo inferencia, es decir, usamos un programa de ordenador que ejecuta un modelo ya entrenado. Durante el entrenamiento se calcularon los valores de miles de millones de parámetros para ajustar un tipo de modelo muy complejo denominado LLM (Large Language Model) a unos datos que eran básicamente toda la información de la web. Podría parecer que chatGPT es inteligente pero solo está ejecutando un modelo que se ha ajustado a todo el conocimiento disponible en la web y que hace inferencia ante las preguntas que se le plantean.
¿Cómo ha sido posible este salto en menos de 30 años? Pues como todos los avances científicos y tecnológicos del ser humano, se debe a un conjunto de factores que básicamente podríamos reducir a dos: por un lado, nuevos modelos matemáticos capaces de establecer patrones a partir de datos tan complejos como textos en lenguaje natural o imágenes; y, por otro lado, nuevos dispositivos hardware capaces de procesar esos datos de una forma suficientemente eficiente.
No es objetivo de este texto entrar en detalles técnicos que además son fácilmente alcanzables con una búsqueda básica en Internet. Sin embargo, deben mencionarse, al menos, los modelos conocidos como redes neuronales profundas, evolución de las redes neuronales concebidas en los años 60 del siglo pasado. El llamado deep learning estableció a principios de este siglo el uso de redes neuronales con miles de capas y nodos capaces de modelar sobre todo imágenes que hasta ese momento tenían difícil tratamiento. Pero estos modelos no hubieran pasado de simple teoría si no es por los chips conocidos como tarjetas gráficas (GPU) y posteriormente las unidades tensoriales (TPU). Estos chips están especializados en la paralelización de operaciones matriciales fundamentales en el entrenamiento de las redes neuronales. El paso definitivo para la IA generativa lo han dado las redes conocidas como transformers. Estas redes incorporan un mecanismo de atención que permite al modelo comprender el contexto. En estos modelos la información no tiene solo un valor por sí misma, sino que la posición y el entorno la definen con mayor claridad. Esto permite sobre todo en el procesamiento del Lenguaje Natural la desambiguación de palabras por su posición y contexto, que es primordial en su comprensión.
El último avance de la IA son los modelos generativos multimodales que permiten generar imágenes o vídeos a partir de texto o “explicar” una imagen, convirtiendo su descripción en texto mediante una mezcla de modelos que ajustan imágenes a su descripción textual y viceversa. La etiquetación de imágenes es un proceso anterior al de la IA generativa y es la base de herramientas posteriores como Dall-e. Recordemos que una imagen no es más que una tabla bidimensional de valores numéricos y que un vídeo no es más que una secuencia de imágenes. Los modelos que permitieron “ver” imágenes son fundamentalmente las redes neuronales convolucionales que tienen un proceso de filtrado jerárquico, capaz de resumir las características más significativas de una imagen.
Finalmente, y de manera breve, hay que señalar que la IA, como toda actividad humana, tiene también su “lado oscuro”. Básicamente son tres los problemas que se le atribuyen:
- Problemas éticos y legales, fundamentalmente derivados de derechos de propiedad intelectual y del posible uso de la IA para cometer delitos.
- Problemas medioambientales, debido al uso excesivo de recursos hídricos y energéticos de los centros de datos que soportan el entrenamiento y despliegue de la IA.
- El impacto sobre el mercado laboral, ya que el uso de estas herramientas aumenta enormemente la productividad de numerosos nichos de trabajo: administrativos, traductores, programadores, publicistas, o incluso profesores y actores. Esto podría conllevar una contracción en la necesidad de estos perfiles a corto/medio plazo.
En posteriores entradas a este blog se abordarán estos problemas y también cuál es el futuro inmediato de la IA: los agentes inteligentes.
